Amazon Bedrock vs Azure OpenAI: Pricing Considerations
Amazon Bedrock shakes up the Generative AI landscape with highly cost competitive models.

Amazon has been questioned repeatedly by analysts and its own customers about its AI efforts. A quick listen to its Q3 earnings call tells you they're listening. Much of Amazon's efforts around Generative AI have culminated in two important releases: Bedrock and Titan.
But shipping AI and winning real-world customers are two very different things. How does Bedrock stack up against OpenAI? Bedrock has more model choices, which can correspond to cost savings.
Editor's Note: Amazon and Azure are continuously unveiling changes and releases to their AI services. To ensure you receive the most up-to-date and accurate information, we will be updating sections of this blog regularly. As we make these updates, we will mark the revision date on a section-by-section basis.
Types of Generative AI Models Available in the Cloud
Generative AI encompasses several categories of models available via OpenAI and Bedrock:
- Image Generation: As the name suggests, image generation models, such as Stable Diffusion and DALL-E, are designed to create images based on textual descriptions or other image inputs.
- Large Language Model (LLM): These models are extensively trained on vast text data and understand/produce textual content. LLMs power ChatGPT, the most popular consumer-facing Generative AI model.
- Base Model: A Foundation Model that serves as a starting point for further fine-tuning.
- Embeddings: Embeddings models are not focused on generating text, but on representing text or data in a numerical way that captures semantic relationships, e.g. "king" + "woman" = "queen".
- Text Generation: Specializes in producing human-like text.
- Transcription: These models convert audio into text.
Amazon Bedrock
Bedrock is a fully managed, serverless service, that provides users access to FMs from several third-party providers and from Amazon through a single API. After you select a FM to use you can privately customize it and connect your propriety data sources and knowledge bases.
Bedrock Supported Models
Table of supported Bedrock models (updated 6/28/24). There may be several versions in each model family, check the models page for specifics and the most up-to-date information.
Azure OpenAI
Azure OpenAI is a partnership between Azure and OpenAI that enables Azure users to use OpenAI via an API, Python SDK, or their web-based interface while authenticated with their Azure cloud credentials. Azure OpenAI distinguishes itself from OpenAI by offering co-developed APIs, enhanced security, and private networking. Throughout this article, the term "OpenAI" refers exclusively to Azure OpenAI for the sake of brevity.
OpenAI Supported Models
Table of supported Azure OpenAI models (updated 6/28/24). Check the models page for specifics and the most up-to-date information.
Amazon Bedrock vs Azure OpenAI Functionality
OpenAI certainly has a lot of name recognition. Due to this people have a conception that it is leaps and bounds ahead of other Generative AI services. However, as Randall Hunt, VP of Cloud Strategy and Innovation at Caylent, relayed on in Yan Cui’s Real-World Serverless podcast, “There wasn’t anything crazy great about the way OpenAI did anything, it just happened to be one of the first times we could see the power of these LLMs through an interface.” Still, GPT-4o is generally recognized as the leader in terms of pure quality.
Service Comparison
Let’s compare some functionality on the service and model level to see how they fare. As this is the cloud, when comparing Bedrock to OpenAI we need to consider things like supported regions and security.
- Documentation/Community: Documentation and community support are challenging to quantify precisely, but based on anecdotal assessments, it's fair to say that the documentation for both services is satisfactory at best. There is a lot of missing information and instructions that are all over the place. This is likely because both services and the models within the services are so new and constantly changing.
- No-Code Playgrounds: While both services are accessible via APIs and SDK as well, a no-code playground can be a helpful interface to utilize some of the models.
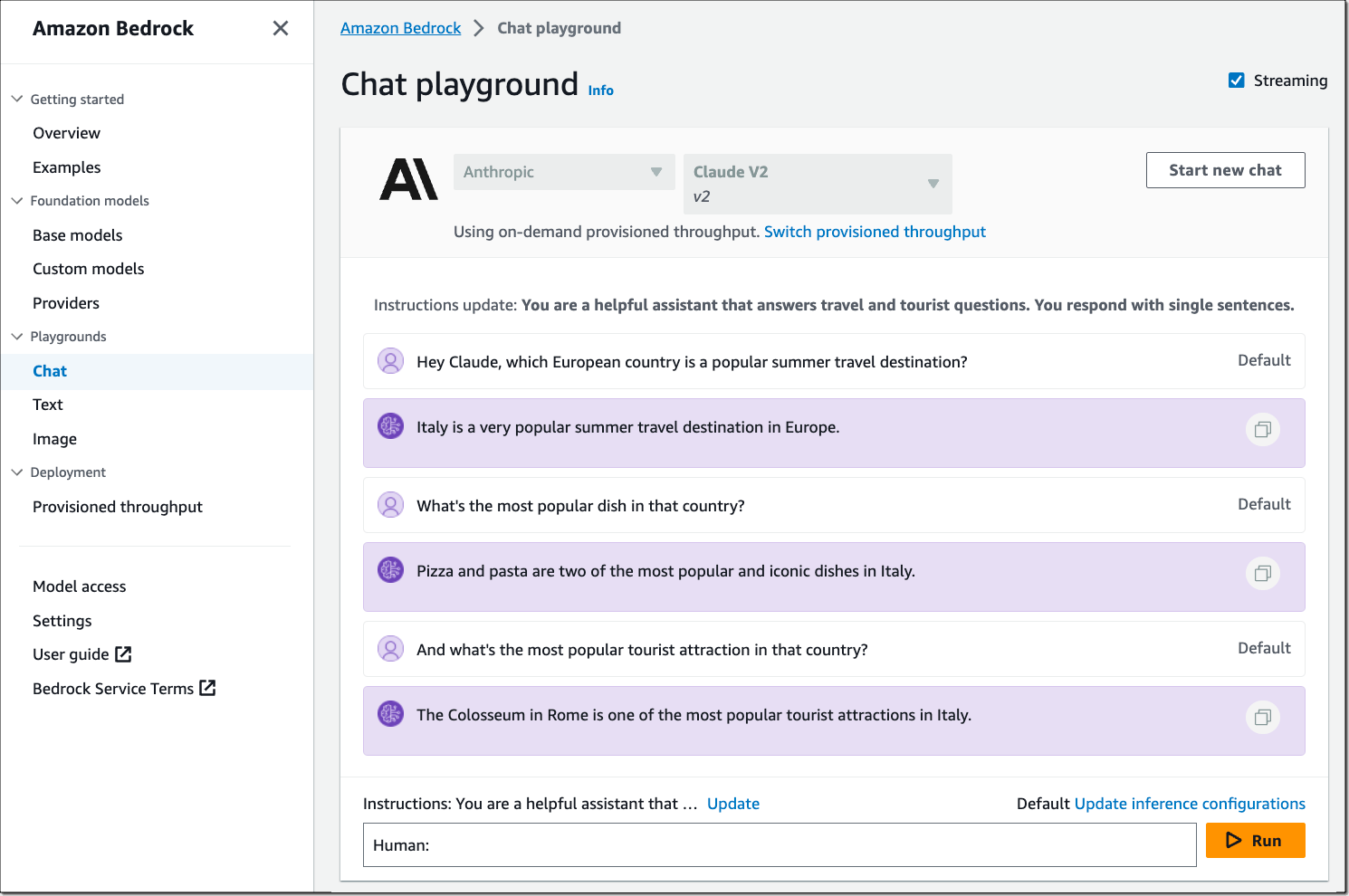
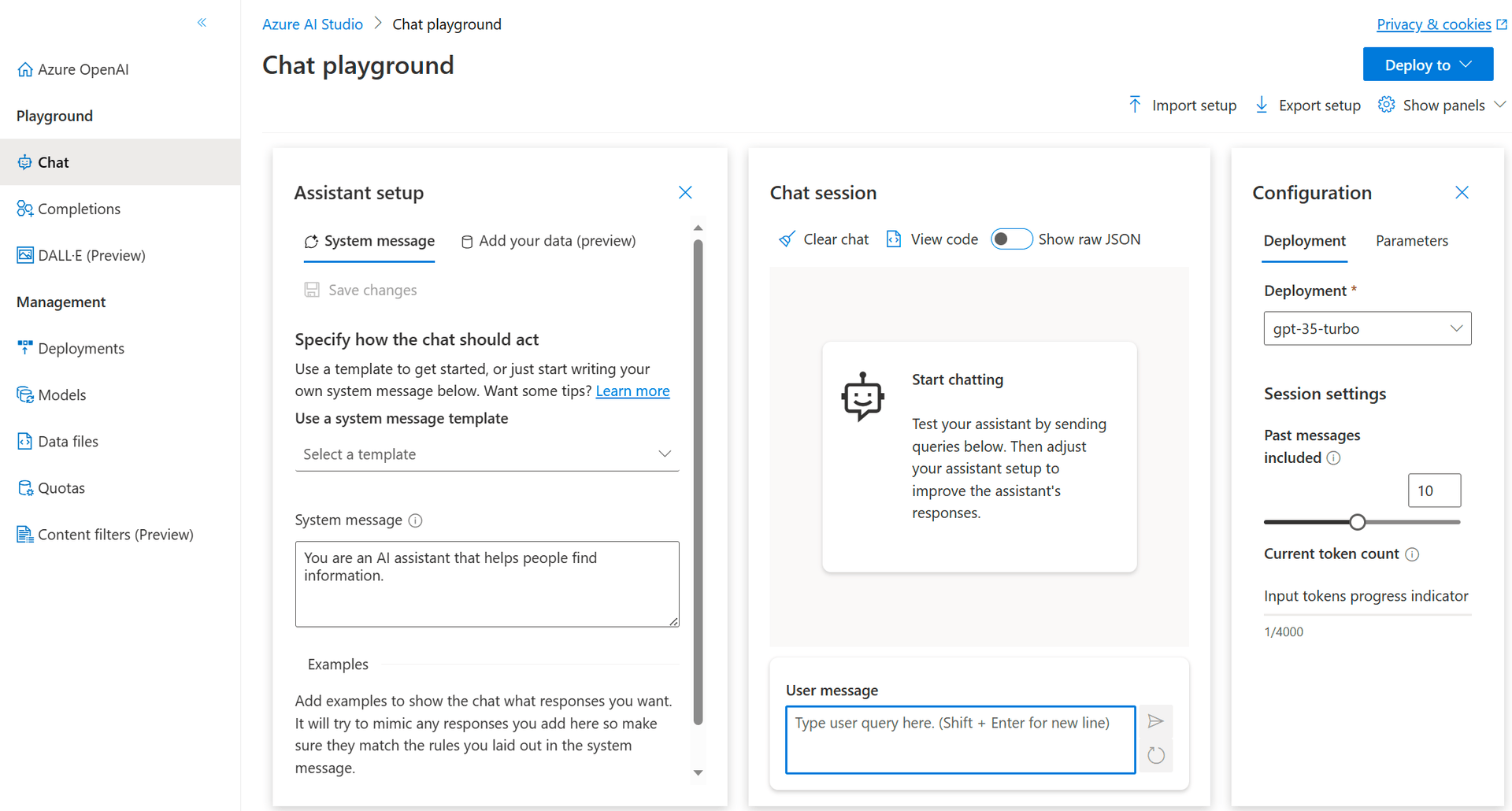
- Provisioned Throughput: Bedrock offers a Provisioned Throughput payment plan for some model types that is advantageous for large workloads.
Model Comparison
(Updated 1/9/24)
Similarly, there are several factors to take into consideration when comparing models within their respective categories, such as max tokens, supported languages, and training data date. Later, we’ll go in-depth on pricing and performance.
- Max Tokens: Max tokens range for model categories and types.
- Embeddings Models: Bedrock and OpenAI both have models with 8k tokens.
- Image Generation Models: Characters to tokens vary, however, 1000 characters correspond to roughly 250 tokens. So DALL-E has more tokens than Stable Diffusion and Titan Image Generator.
- LLMs: Both Bedrock and OpenAI provide models with 4k and 8k token options. OpenAI extends the range with 16k and 32k tokens. Bedrock and OpenAI offer models with 100k and 128k tokens, respectively, (corresponding to an impressive 300 pages). However, the Claude model takes the trophy with an impressive maximum capacity of 200k tokens. That corresponds to 500 pages of information.
- Supported Regions: Bedrock is available in Asia Pacific (Singapore), Asia Pacific (Tokyo), AWS GovCloud (US-West), Europe (Frankfurt), US East (N. Virginia), and US West (Oregon). OpenAI regions vary per model as follows:
Azure OpenAI supported models by region (as of 1/9/24). Note that model availability may vary based on the region and service, and there may be certain limitations in some regions.
- Supported Languages: Bedrock language capacity is model-specific. Command, Embed - English, Llama 2, Stable Diffusion, Titan Image Generator, Titan Multimodal Embeddings, and Titan Text Lite support only English. Jurassic supports 7 languages, Claude supports 12+, Titan Embeddings supports 25+, while Embed - Multilingual and Titan Text Express support over 100. See the model pages for the specific languages. OpenAI has less information available on which languages are supported, however, this response claims it is available for use in a variety of languages.
- Training Data Date: OpenAIs models Ada, GPT-3.5 Turbo, GPT-4, and the Base Models are trained until Sept 2021. GPT-4 Turbo is trained until Apr 2023. Bedrock’s training data date was a little harder to find, we had to go to the retrospective provider's sites to find that the only publicly available dates are Claude’s (December 2022) and Jurassic's (current up to mid-2022).
Bedrock Pricing
Charges for Bedrock are applied for model inference and customization. There are two plans available for model inference, On-Demand and Provisioned Throughput. Model customization and Provisioned Throughput are not available for all models. Price varies per region.
On-Demand
The non-committal, pay-by-usage option. Charges vary depending on the model type. Text generation models incur charges per input token processed and output token generated. Embeddings models charge per input token processed. Image generation models charge per image generated.
Bedrock On Demand LLMs pricing table. (Updated 6/28/24).
Bedrock On Demand Image Generation Models pricing table. (Updated 6/28/24).
Provisioned Throughput
You have the option to buy model units (specific throughput measured by the maximum number of input/output tokens processed per minute) for a specific model (including custom models). Pricing is charged hourly and you can choose a one-month or six-month term. This pricing model is best suited for “large consistent inference workloads that need guaranteed throughput.”
Bedrock Provisioned Throughput Models pricing table. (Updated 6/28/24).
Model Customization
You’re charged for model customization based on the number of processed tokens and model storage. Keep in mind, inference on more than one model unit is only available for Provisioned Throughput.
Bedrock Model Customization pricing table. (Updated 6/28/24).
Azure OpenAI Pricing
Charges for OpenAI are fairly simple. It is a pay-as-you-go, with no commitment. There are additional customization charges. Price varies per region.
Pay-As-You-Go
Charges vary for different model types and if applicable, context. Text generation models charge per prompt tokens and completion tokens. Embeddings models and base models charge per usage tokens. Image generation models charge per 100 images generated.
OpenAI Pay-As-You-Go LLMs pricing table. (Updated 6/28/24).
OpenAI Pay-As-You-Go Image Generation Model (Dall-E) pricing table. (Updated 6/28/24).
OpenAI Pay-As-You-Go Speech Generation Model (Whisper) pricing table. (Updated 6/28/24).
Model Customization
Model customization charges are based on training time and hosting time with slightly different pricing per region.
OpenAI Model Customization pricing table. (Updated 6/28/24).
Pricing Comparison: Bedrock vs OpenAI
(Updated 1/9/24)
On a model-by-model comparison, Bedrock is most often cheaper than OpenAI. However, cost does not tell the full story and the scenarios below are based purely on an analysis of pricing.
Standard Context Window: Command, Llama 2, Titan Text vs GPT-3.5 Turbo 4k
For a lower capacity model where we want to perform tasks such as chat, summarization on an article-length passage, Q&A, etc, we can consider one of the models with a 4k token max. There is one model from OpenAI that fits the criteria—GPT-3.5 Turbo 4k, and multiple of Bedrock—Command, Llama 2, Titan Text Lite, and Titan Text Express. The pricing for Command and GPT-3.5 Turbo 4k are the same, at $0.0015 per 1000 input tokens and $0.002 per 1000 output tokens.
Titan Text Lite, which can perform many of the same capabilities is much cheaper at $0.00015 per 1000 input tokens and$0.0002 per 1000 output tokens. Llama 2 is $0.00075 per 1000 input tokens and $0.001 per 1000 output tokens. Another option is Titan Text Express, the difference between the Lite version is that it has retrieval augmented generation ability and a maximum of 8k tokens. The price is $0.0008 per 1000 input tokens and $0.0016 per 1000 output tokens, cheaper than GPT-3.5 Turbo 4k.
Chatbot Scenario: Titan Text Express vs GPT-3.5 Turbo 4k
Consider a scenario where you want to develop a simple customer service chatbot. The chatbot will need to be able to handle customer inquiries, provide assistance, and answer questions on a range of topics related to your products and services. The model will need to handle short sentences as well as more detailed discussions.
A standard question could be about 15 tokens and the answer could be 85. If your chatbot is answering 250,000 similar tokened questions a month the estimated price would be:
15 tokens X 250,000 questions = 3,750,000 input tokens
85 tokens X 250,000 answers = 21,250,000 output tokens
Titan Text Express: 3,750,000 input tokens / 1000 X $0.0008 + 21,250,000 output tokens / 1000 X $0.0016 = $37
GPT-3.5 Turbo 4k: 3,750,000 input tokens / 1000 X $0.0015 + 21,250,000 output tokens / 1000 X $0.002 = $48
GPT-3.5 Turbo 4k is 30% more than Titan Text Express, making Bedrock the cheaper option for a lower-capacity model.
Long Context Window: Long Context Window: Jurassic-2 vs GPT-4 8k
For more advanced tasks such as advanced information extraction, draft generation, and summarization on larger passages, let’s compare some of the models with an 8k token max. Between the Jurassic-2 models the Ultra model stands out because of intricate ideation, and therefore compares well with GPT-4 8k. Jurassic-2 Ultra is much cheaper at $0.0188 per 1000 input tokens and $0.0188 per 1000 output tokens when compared to GPT-4 8k’s $0.03 per 1000 input tokens and $0.06 per 1000 output tokens.
Long Context Window: Claude Instant vs GPT-3.5 Turbo 16k
For even larger tasks consider Claude Instant (100k token max) and GPT-3.5 Turbo 16k (16k token max). The capabilities and pricing are relatively similar. However, the choice is much more case-dependent since with Claude Instant you are charged $0.0008 per 1000 input tokens and $0.0024 per 1000 output tokens, compared to $0.003 per 1000 input tokens and $0.004 per 1000 output tokens for GPT-3.5 Turbo 16k. So, because of the lower pricing, Claude Instant would be a great choice with a higher token input amount and lower output token amount.
Extra Long Context Window: Claude 2.1 vs GPT-4 32k
For high-capacity models with very advanced tasks, such as content generation and complex reasoning, consider Claude 2.1 vs GPT-4 32k. Claude 2.1 has an impressive maximum of 100k tokens, while GPT-4 32k provides 32k tokens. Claude 2.1 is a great choice since it is way cheaper at $0.008 per 1000 input tokens and $0.024 per 1000 output tokens. GPT-4 32k is $0.06 per 1000 input tokens and $0.12 per 1000 output tokens.
Text Summarization Scenario: Claude 2.1 vs GPT-4 32k
You work at a content creation agency and need to summarize lengthy articles and reports for clients. You want to process articles at around 25,000 tokens and summarize them to about 5,000 tokens. If you process 300 articles a month consider the estimated prices:
25,000 tokens X 300 articles = 7,500,000 input tokens
5,000 tokens X 300 responses = 1,500,000 output tokens
Claude 2.1: 7,500,000 input tokens / 1000 X $0.008 + 1,500,000 output tokens / 1000 X $0.024 = $96
GPT-4 32k: 7,500,000 input tokens / 1000 X $0.06 + 1,500,000 output tokens / 1000 X $0.12 = $630
Claude 2.1 is remarkably cost-effective, positioning Bedrock as the more economical choice, with 556% cost savings in this situation.
In terms of functionality, this article does a great in-depth comparison of the the functionality of the two models and concludes that GPT-4 32k performs slightly better. Some takeaways are a similar performance for code generation and conversion, a better performance for GPT-4 32k’s dataset analysis and math skills, and Claude’s 2.1 distinct ability to summarize text over 32k tokens.
Conclusion
There are a number of dimensions to consider when comparing Bedrock and OpenAI, such as region availability, tokens, model quality, and price. Based on the variety of models, lower price, and large token max from the Claude Model, we think Bedrock is increasingly competitive for applications where the absolute best performance is not required.
Sign up for a free trial.
Get started with tracking your cloud costs.


