Optimizing Large Language Models for Cost Efficiency
5 techniques to reduce the cost of using large language models in your applications.

Aman Jha, the creator of explainpaper.com, recently shared the eye-opening bill for one month of usage for his popular OpenAI-driven paper summarization and Q&A application.
We love to see it pic.twitter.com/Gobvabp1BA
— Aman Jha (@amanjha__) March 21, 2023
For some developers, OpenAI costs are surpassing AWS costs as the top-line item for cloud infrastructure expenses. The deluge of developer activity on OpenAI APIs and frameworks like LangChain has created a new class of apps. Large Language Models (LLMs) make it possible to build chatbots for HN and create AIs that can have complex emotional conversations.
LLMs use a consumption pricing model that charges based on the amount of text characters (tokens) exchanged between the application and the AI. Each AI has a fixed "token window" for the context length the model can retain for the current task. For example, GPT-4 can use 8,192 tokens to store the conversation history of a chat. Even though the context length is fixed, the prompt length and response length are unpredictable. These unique billing parameters have resulted in a flurry of new cost-optimization techniques for developers working with LLMS.
Some of these LLM cost-optimization techniques include:
- Prompt Engineering
- Caching with Vector Stores
- Chains for Long Documents
- Summarization for Efficient Chat History
- Fine Tuning
Let's take a deeper dive into the pricing models, and then look at how to use these techniques to improve the cost efficiency of your LLM applications.
Pricing for OpenAI, Anthropic, and Cohere
OpenAI has APIs for text and images with different pricing. In this post we will focus on the text APIs, including Text Completion, Embeddings, and Fine-tuning. While OpenAI was first to market, Anthropic and Cohere offer comparable APIs for interacting with their LLMs.
Tokens
The text APIs charge per token, where OpenAI defines a token as roughly “four characters”. To get a sense of how many tokens are in a block of text you can use a tokenizer. Pasting this paragraph here into the Tokenizer counts 77 tokens, so this block of text would cost $0.00231 to pass to GPT-4.
OpenAI Pricing
The first three models in the table below are for the Completions API which is used to answer questions, summarize documents, and generate text. The Embeddings and Fine-tuning APIs are used to provide additional context and training data to the model.
* GPT-4 has different pricing for prompts and completions, charging $0.03 per 1000 prompt tokens and $0.06 per 1,000 completion tokens.
You can see the cheapest model by far is gpt-3.5-turbo which is the same model that is running in ChatGPT. The new GPT-4 model is much more expensive but provides stronger logical reasoning capabilities and has a larger token window. The Embeddings and Fine-tuning APIs run the oldest models from the GPT-3 series.
Anthropic and Cohere Pricing
Let’s examine the pricing of two startup OpenAI competitors. Anthropic prices per million tokens while Cohere uses “Generation Units”. The table below normalizes these into 1,000 tokens. Claude from Anthropic is a large language model that also comes in an "instant" version which would be s smaller, faster model. Cohere separates their endpoints by task and possibly by model, so the Generate and Summarize endpoints have different pricing.
You can see that claude-instant-v1 is slightly cheaper than gpt-3.5-turbo while Cohere's endpoints are slightly more expensive. The AI space is moving incredibly quickly at the moment but you can get a sense of how to compare the performance of the different models in this post from LessWrong.
Optimizing Large Language Models
Given these pricing dimensions, the goal of cost optimization is to use the minimum number of tokens to complete the task at high quality. The techniques below are roughly ordered from easiest to most difficult to implement.
Prompt Engineering
The prompt is the starting point for instructing the model what to do. For example, we have been experimenting with a Q&A bot which contains a prompt like the following, adapted from the Supabase Clippy prompt:
Example prompt for a Q&A bot.
The prompt is included in the token count. In the example above, this prompt would be sent every time a user submitted a question to our chatbot. Prompt engineering is an emerging field which seeks to discover and produce the best results from LLMs by modifying the prompt. You can use prompt engineering to roughly control the amount of tokens that are returned.
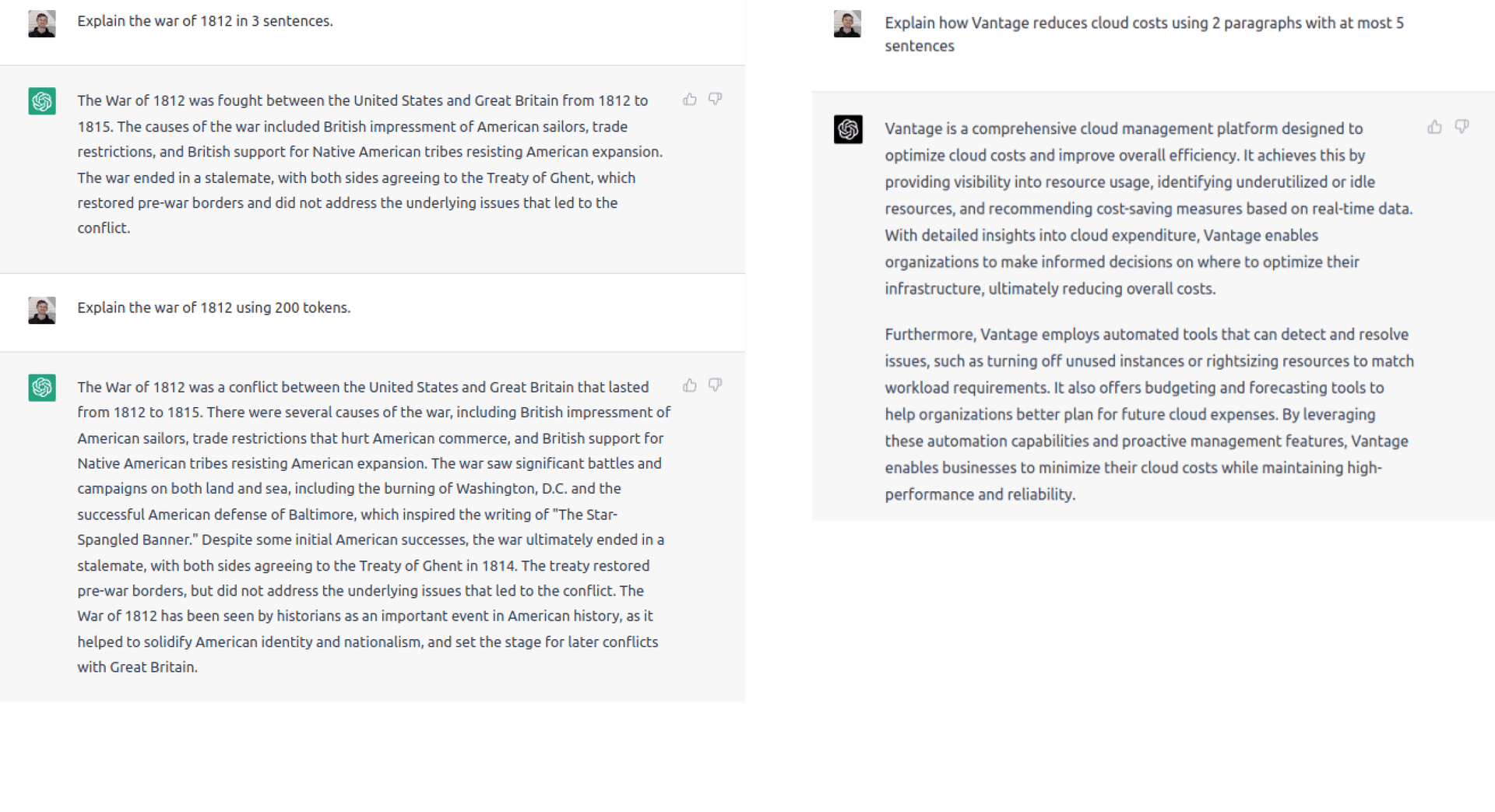
Controlling the amount of output with GPT-3.5 on the left and GPT-4 on the right.
For GPT-3.5 it seemed like we could specify the number of tokens and the model would keep its responses under that amount. For GPT-4, it worked better to specify the amount of output in terms of the number of paragraphs and to use phrases like "be concise", "summarize", and so on.
In this way, you can establish a "token budget" for your applications and then estimate the number of messages that will be sent based on how many users you have and their average usage.
Caching with Vector Stores
Vector stores are databases which store large arrays of numbers. They are a key piece of infrastructure for working with LLMs and using them properly can result in large cost savings versus making many API calls to foundational models.
Popular vector database include Pinecone, Weaviate, and Milvus. You can think of the role of vector databases in these applications as “caching for large language models”.
Loading markdown documents into a vector store using Python.
By splitting a corpus of documents into chunks, creating embeddings for each chunk, and vectorizing user queries that come in, it's possible to reduce the amount of context that needs to be passed to the model to answer questions.
In the code above, we have a preprocessing step to remove elements like newlines before loading them into vector stores. This further lowers costs by reducing storage space requirements, as the cleansed data occupies less space. Fewer documents to load also means lower Embeddings API costs which come at $0.0004 per 1,000 tokens.
Chains for Long Documents
What if the amount of text is greater than the maximum context length? In other words you may have a large PDF document or a set of markdown files that compromise the documentation for a product. For explainpaper.com, a user may ask the AI summarize the entire paper.
To accomplish a task like this, you can use chains that repeatedly call LLMs and have different tradeoffs in terms of cost and performance. Greg Kamradt from Data Independent reviews these techniques and how to implement them in a YouTube video.
- Map Reduce - This classic process splits the large document into smaller ones, creates summaries for each section, and then creates summaries of those summaries until you have a summary of the entire document. While this can be done quickly in parallel, it also loses a tremendous amount of information and requires many API calls.
- Refine - Refine builds one summary of one section at a time, appending each previous summary to the current section synchronously. This maintains the context of the document better but takes longer to complete. It uses fewer tokens then map reduce and is cheaper. You can think of it like an O(N) search for the answer.
- Map Re-Rank - If the question is anything other than "summarize the entire document", map re-rank is the most cost efficient method. It summarizes 2 sections at a time and choses the summarization it has the highest confidence that it contains the answer in. You can think of this method as O(log(N)) search for the answer.
While these techniques are state-of-the-art for now, they may not last. GPT-4 has a variant with a 32K token window at $0.12 per 1,000 tokens. That means you can fit roughly 50 pages of text into 1 token window.
Summarization for Efficient Chat History
As discussed above, a limitation of large language models is the “token window” which is about 8K tokens for GPT4 or 4K tokens for GPT3.5. For chatbots, that window is all of the “knowledge” that the model will have about the chat conversation it's carrying out. Obviously that is problematic for use cases like coding agents which may be with a programmer throughout a long session or support chats which could number in the hundreds of messages.
Even if the conversation can fit within the chat window, the way that chatbots today “remember” the conversation is by passing the entire history of it into the token window. That means that in a typical chatbot implementation, the longer the conversation goes on, the more it costs. This diagram visualizes what’s happening here.
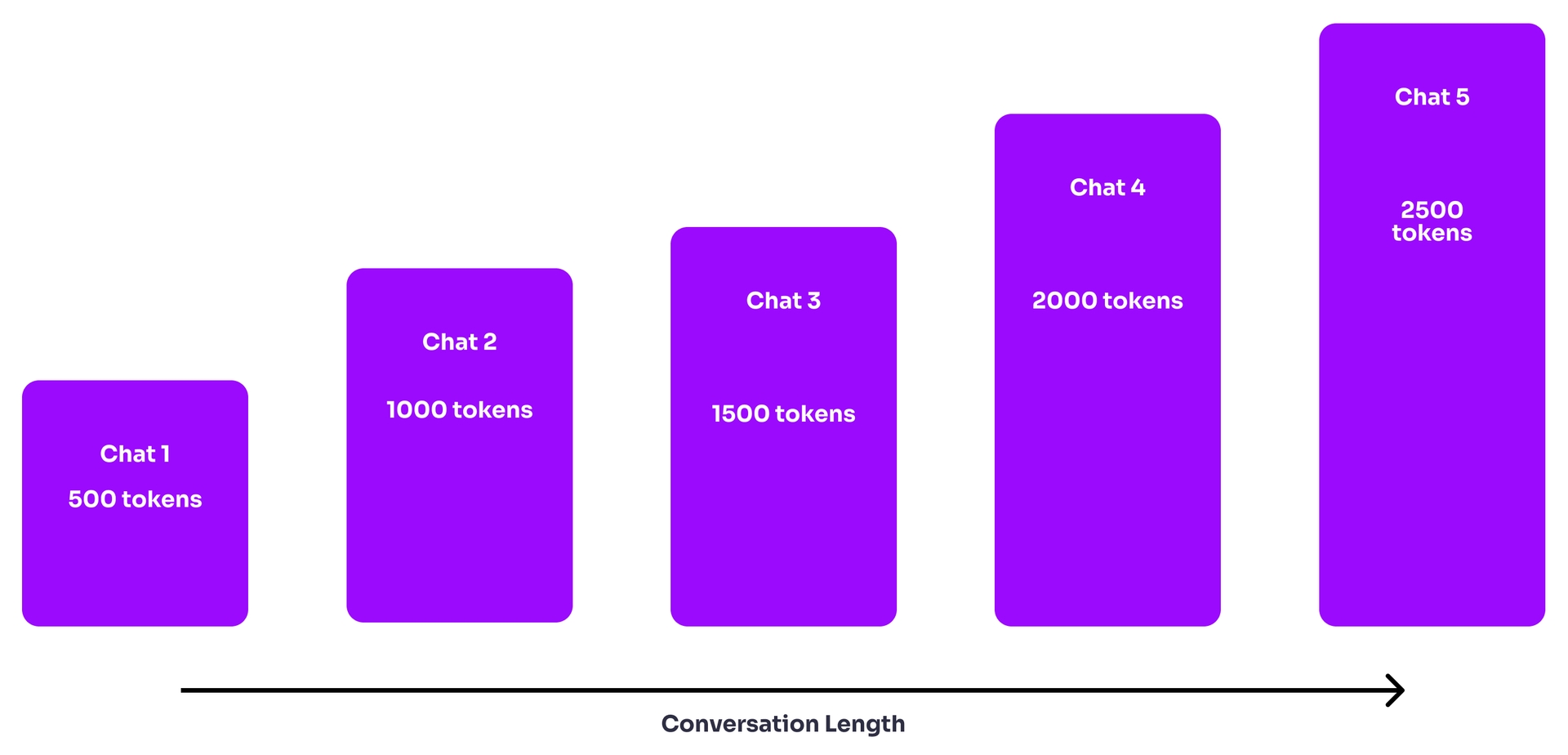
Without intermittently summarizing the chat history, the chat conversation will grow more costly with each message.
To save on tokens, we can use the chat APIs themselves. Every N messages in the chat, you can take the whole of the previous conversation and summarize it, using the summary as the context for resuming the conversation and reducing the token count that is passed to the API and saving money. See an example implementation of this here.
But this has one issue. You may lose critical bits of information from the chat, especially as the summarization proceeds forward over multiple N sized windows. A more advanced technique which still ultimately saves money is to create vectors for the chat history and - for each chat - create a vector for the current conversation and look up all the most similar vectors from the stored chat history. Those can then be passed to the API as context for the prompt.
Fine Tuning
At a certain point, the data you have may be specialized enough that the Fine-tuning API makes sense. In other words you may wish to have the model already know the context it needs without doing embeddings or summarization. An example of this would be a chatbot for insurance claims. A large insurance company could choose to simply fine tune their model on their own data.
To understand pricing here you need to understand that the fine tuning endpoint charges per 1000 tokens but trains on the data in multiple passes. By default, n_epochs is set to 4 which means that the cost of fine tuning your data will be roughly 4X times the amount of data you have.
Note that at the time of this writing, a limited number of models are available for this endpoint. Once the data has been fine tuned, accessing your specific endpoint is more expensive as well. The DaVinci model from OpenAI costs $0.03 per 1,000 tokens to train and $0.12 per 1,000 tokens to query.
Conclusion: Models Rule Everything around Me
An interesting aspect of the cost optimization techniques above is that each uses the model itself to reduce costs. Whether through prompt engineering, embeddings, summarization or fine tuning, the key to building efficient LLM applications is to offload the optimizations to the model and let the AI do the work for you.
In some ways, this is like any other part of software engineering where you can save money by moving compute closer to data. In data work for example developers may have a more complex SQL query in their database versus iterating over results in the backend. Although we seem to be entering a new era in the technology industry it's good to see that the fundamentals of building cost efficient applications remain the same.
Sign up for a free trial.
Get started with tracking your cloud costs.



