Querying a Billion Rows of AWS Cost Data 100X Faster with DuckDB
DuckDB was 4X to 200X faster than Postgres for analyzing cloud cost data for the Q4 2022 Cloud Costs Report.

Recently we released the Q4 Cloud Costs Report which uses a sampling of real-world, anonymized data to quantify how cloud spending is changing. A sampling of cost data from Vantage's data warehouse is anonymized, aggregated, and exported resulting in over 1 billion rows to analyze. From simple reads to complex writes and data ingestion we found that DuckDB was between 4X and 200X faster than Postgres for this use case.
In our Q3 Cloud Costs Report, we used PostgreSQL running locally on an M1 laptop to explore the data to find insights and ultimately build the report. The performance of PostgreSQL for this use case was abysmal, often taking more than 20 minutes to run a query and consuming nearly the entire disk to store the data.
For the Q4 report, we switched database technologies to DuckDB, a new in-process OLAP database with a column-store architecture. DuckDB allowed us to query the entire dataset in seconds, store the entire dataset efficiently on local machines, and make it significantly faster to build and publish the Q4 Report.
Query Performance
The sampling dataset for the Q4 report contains over one billion rows, which we can examine by running a SELECT COUNT(*) query. Right away we get the advantages of using a column-store database. Comparing Postgres and DuckDB query performance for this basic query we see a stark difference.
Postgres takes over 6 minutes to count the number of rows:

Time for SELECT COUNT(*) on 1 billion rows in Postgres.
DuckDB returns the count in a little under 2 seconds, or 200X faster than Postgres:

Time for SELECT COUNT(*) on 1 billion rows in DuckDB.
A more complicated query involving GROUP BY, subqueries, and string comparisons is used to calculate the chart below which shows the percentage above average of compute spend on Black Friday and Cyber Monday compared to the average daily spend for the quarter.
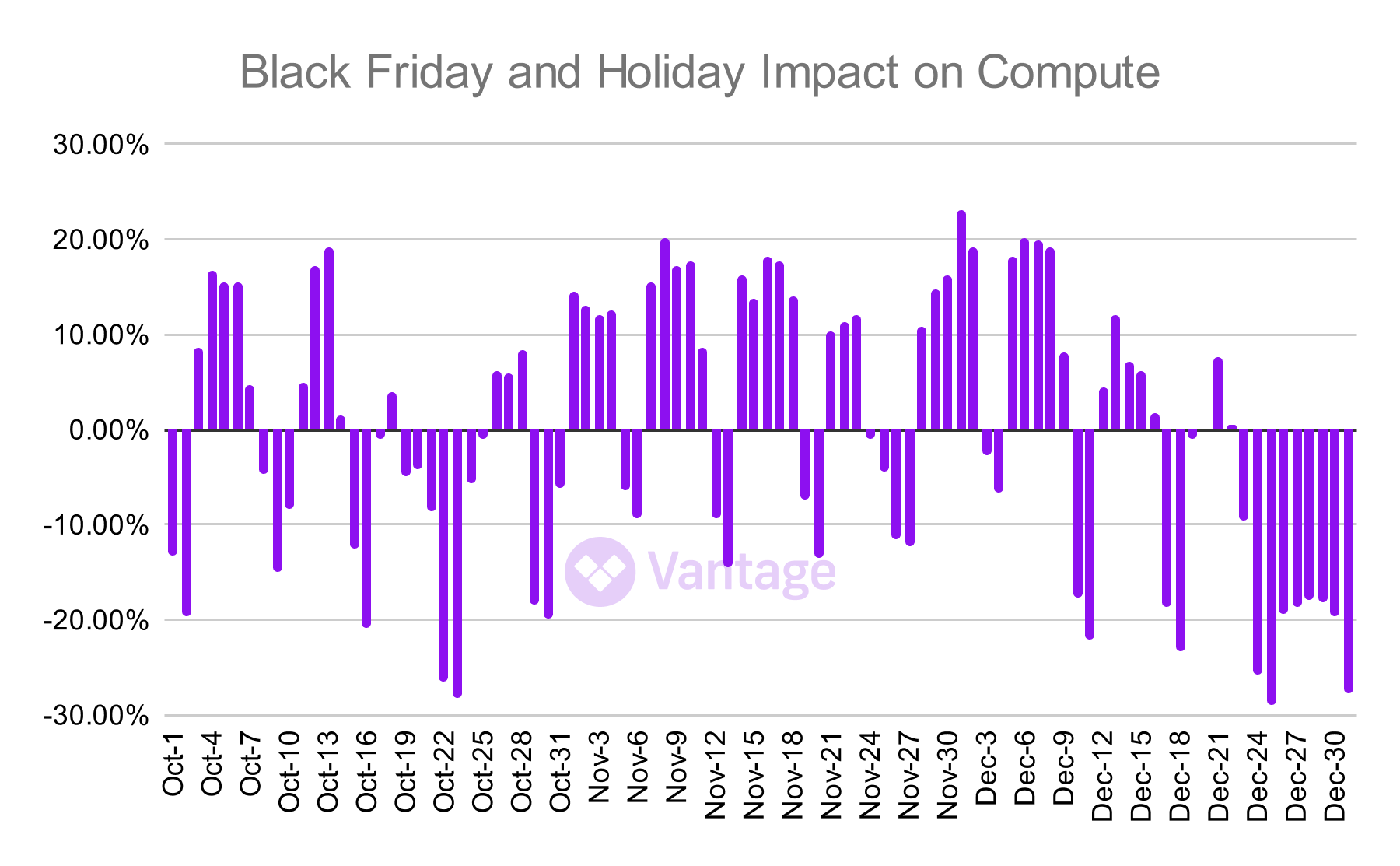
Graphing the daily percentage higher or lower than average for compute spend in Q4. The query to produce this involves several more complicated SQL expressions but DuckDB still returned the data in seconds.
Postgres takes 7 minutes, 22 seconds to return data while DuckDB comes back in 4 seconds, for a 110X faster query in DuckDB. This also means that subsequent data explorations on Black Friday and holiday data could be done in nearly real time.
What about write performance? To graph the popularity of different instance types over time, we have to parse out the instance family from the instance name, for example c5d from c5d.2xlarge. A derivative table is created for convenience using CREATE TABLE AS.
Postgres takes a little over 8 minutes to write this new table:

Measuring write performance for a derivative table in Postgres.
DuckDB takes roughly 80 seconds meaning DuckDB was 6X faster than Postgres working with derivative tables:

Measuring write performance for a derivative table in DuckDB.
We will note that the Postgres syntax of split_part() is more convenient than the DuckDB equivalent of array_exctract(str_split()) and this was one of a few queries that needed adjustments from their Postgres equivalents.
Data Ingestion
Not only are queries much faster with DuckDB, loading data is significantly faster as well. This dataset is delivered as several gzipped CSVs which are then uncompressed and loaded one by one into the database.
With Postgres, the data load took almost 10 minutes per file, 9 minutes and 26 seconds in the example below:

Time to load a portion of cost data into Postgres.
Additionally, there is no native way to CREATE the table from the CSV, although clunky work-arounds exist.
With DuckDB, the data load took a little over 2 minutes per file, 2 minutes and 15 seconds in the example below:

Time to load the same portion of the cost data into DuckDB.
The DuckDB table can also be created directly from the command, the column types were inferred correctly, and there is a nice progress bar as the load is happening. This meant that DuckDB was 4X faster than Postgres at loading our cost data while providing a better developer experience.
Data Compression
Not only are queries and data ingestion faster, but the default compression of the data on disk is very good with DuckDB.
Postgres does not compress data by default and so the size of the data on disk is roughly the size of the data as an uncompressed CSV, clocking in for this portion of the data at 21 GB:

Size of data on disk with Postgres.
With Postgres 14, LZ4 compression, is now available for columns but it requires recompiling Postgres so this was not tested.
DuckDB reduces the CSV down to a stunning 1.7GB, which is actually smaller than the gzip file that the data was delivered in!

Size of data on disk with DuckDB.
No doubt the column store architecture and the regularity of the data in our dataset helps but by default, DuckDB data is 12X smaller than Postgres on disk.
DuckDB Drawbacks
It’s not all roses with DuckDB. The CLI is still relatively new and sometimes had glitches like the progress bar not completing or hangs or crashes. As mentioned above, more syntax is needed for some queries since Postgres has a richer built-in library of functions. Another column-store database like ClickHouse has over 1,000 built-in functions and would obviate the need to do array operations in many cases.
Other Use Cases for DuckDB
DuckDB can also be run in the browser. This opens up interesting possibilities for other free Vantage tools like ec2instances.info which stores huge amounts of pricing data for AWS and Azure. The site is delivered statically so ideally more complicated pricing comparisons or region comparisons could be done client-side.
The Future of Data Analysis
It is probably fair to say that Postgres was never the right tool for this job but DuckDB definitely is. The biggest analysis improvement was just the fact that the iteration loop for exploring the cost data set was much faster. Indeed, we produced more data for the Q4 Report than we did for the Q3 Cloud Cost Report and did so in a shorter time. Not needing to create derivative tables for most queries and using a fraction of the disk space for the dataset were also big wins. As the amount of cost data Vantage processes grows with the growth of our customer base and the addition of new integrations, we are excited to still be able to process it all in seconds for future reports and applications.
Sign up for a free trial.
Get started with tracking your cloud costs.


