OpenAI Costs Integration: Development Diary
We asked ChatGPT what API endpoint we should use for OpenAI costs and it gave us the answer.

Vantage: How do we access our OpenAI usage data through the API?
ChatGPT: You can access usage via the /usage endpoint.
That was how our OpenAI integration was born. OpenAI never documented this endpoint, so we think ChatGPT just made up the answer, but it turned out to be right. We fired off a GET request to https://api.openai.com/v1/usage?date=2023-4-14, and there it was:
Now we didn't have any data, but we knew something was here. At Vantage, we want to help our customers understand their infrastructure bills in detail, and this seemed like a great opportunity to expose detailed cost data. At the time of writing, OpenAI's Usage dashboard only displays the usage per day in dollars spent, number of requests per hour, and how many tokens were used per model. You can't see show how much you're spending on particular models or operations. This could lead to potentially large bills if you're not careful.
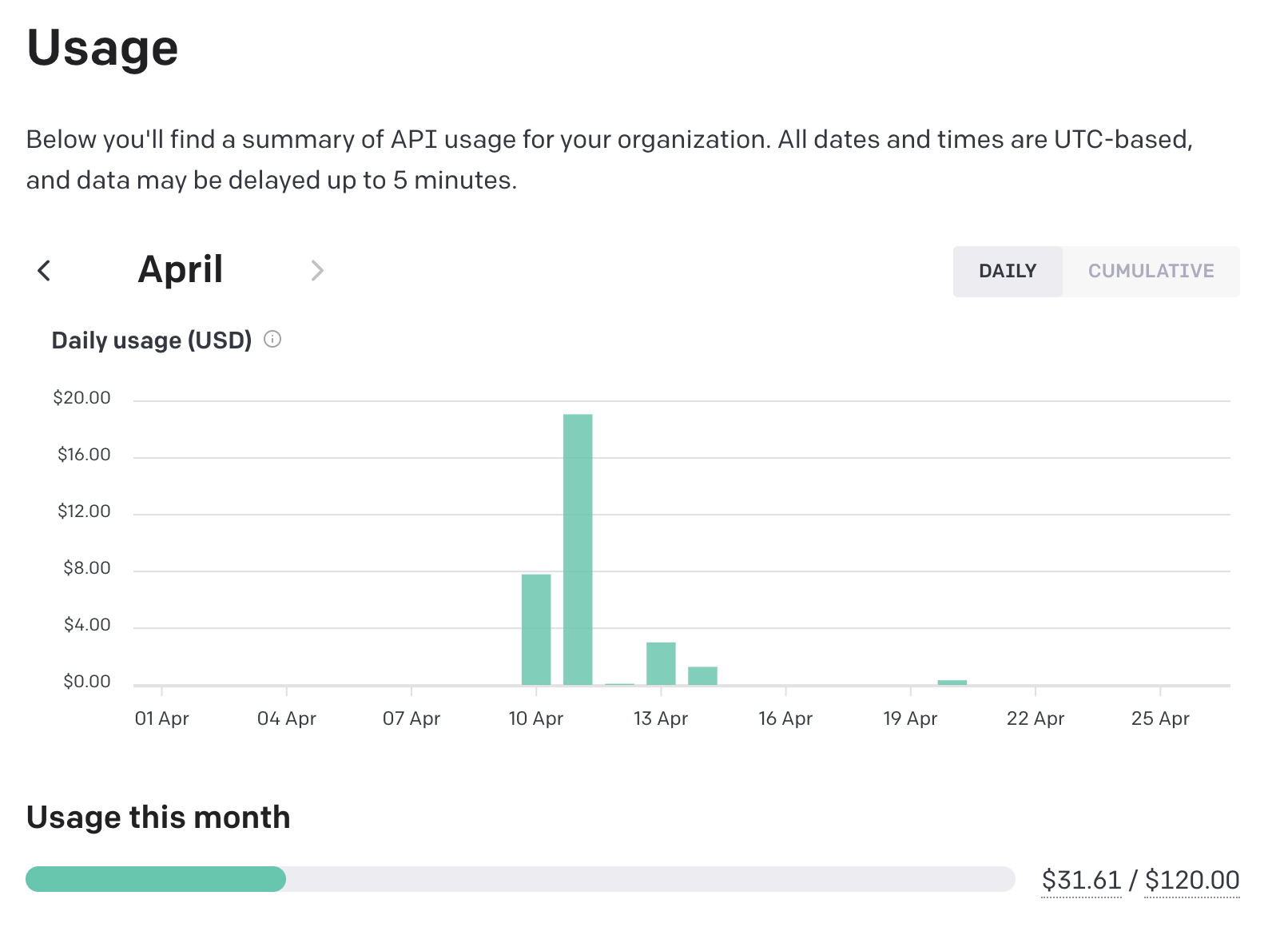
Viewing usage costs in OpenAI's dashboard
Simulating Usage
We started off writing Ruby and cURL scripts that would simulate usage so we knew what the data looked like.
When we started out, we didn't know what any of these fields meant. We asked ChatGPT, but we weren't confident ChatGPT knew the answer either. Ultimately we were able to learn what each field meant, at least in the data field.
The Ruby script below was our starting point. It helped us simulate gpt-3.5-turbo usage by repeatedly calling the chat/completions operation. We ask the bot to talk about itself 10 times in each request. We also set a budget so that the script would not exceed a certain dollar amount.
We let this script run a few cycles and we saw the usage response update:
Now that our API is populated we need to transform these fields into data that Vantage can ingest.
Making Sense of the Data
What did all of these fields mean? We asked ChatGPT, but the answer was so confident that we weren't sure if it was making things up again. We eventually figured it out:
aggregation_timestamp: The timestamp of the usage data. OpenAI aggregates data for each 5 minute period.n_requests: The number of requests made.operation: The operation performed. Possible operations arecompletion(Chat or Completion),edit(Edit or Insert),embeddings. Theoperationfield is only present in thedatafield above.snapshot_id: The model used. There are many models and variations of models, so we ended up using a regex to parse out the base model name.n_context: The number text prompts or examples provided.n_context_tokens_total: The total number of tokens used as context.n_generated: The number of completions generated.n_generated_tokens_total: The total number of tokens generated as part of the response.
As you can see, we're able to calculate the cost by summing the n_context_tokens_total and the n_generated_tokens_total. OpenAI aggregates data in 5 minute increments and will conveniently sum up all the usage in that time period. The OpenAI pricing page provides costs for each model.
But how do you verify that you arrive at the right answer? Sadly, that isn't possible. The current_usage_usd is not implemented as of writing this blog post, and we weren't able to find out from anyone at OpenAI if or when it would be usable. We can't verify the cost data because OpenAI will always return 0 for the current_usage_usd of that day. We were expecting it to return the total dollar amount for the day. We were able to get very close on all of our customers' accounts and matched it exactly on our own account.
We relied on cURL to simulate usage data for operations like Image generation and Speech to text. We did this because OpenAI does not have an official Ruby gem for their API, and the unofficial gems we tried didn't work.
Once we had sample usage data, we started building out the ETL pipeline. The crux of the work was transforming on the costs. We eventually settled on a regex pattern to parse out base models and calculated the cost from the operation and model. There are some other gotchas to watch out for, like how GPT-4 charges separately for the context and completion tokens.
Most operations will follow a similar pattern, but for image generation, audio translation and transcription, and fine-tuned training, we see the following sample responses:
The cost calculations are straightforward here. OpenAI charges by the image, the minute, and the trained tokens for DALL-e, Whisper, and GPT3 models respectively.
And now here's what it looks like once we've generated a cost report in Vantage:
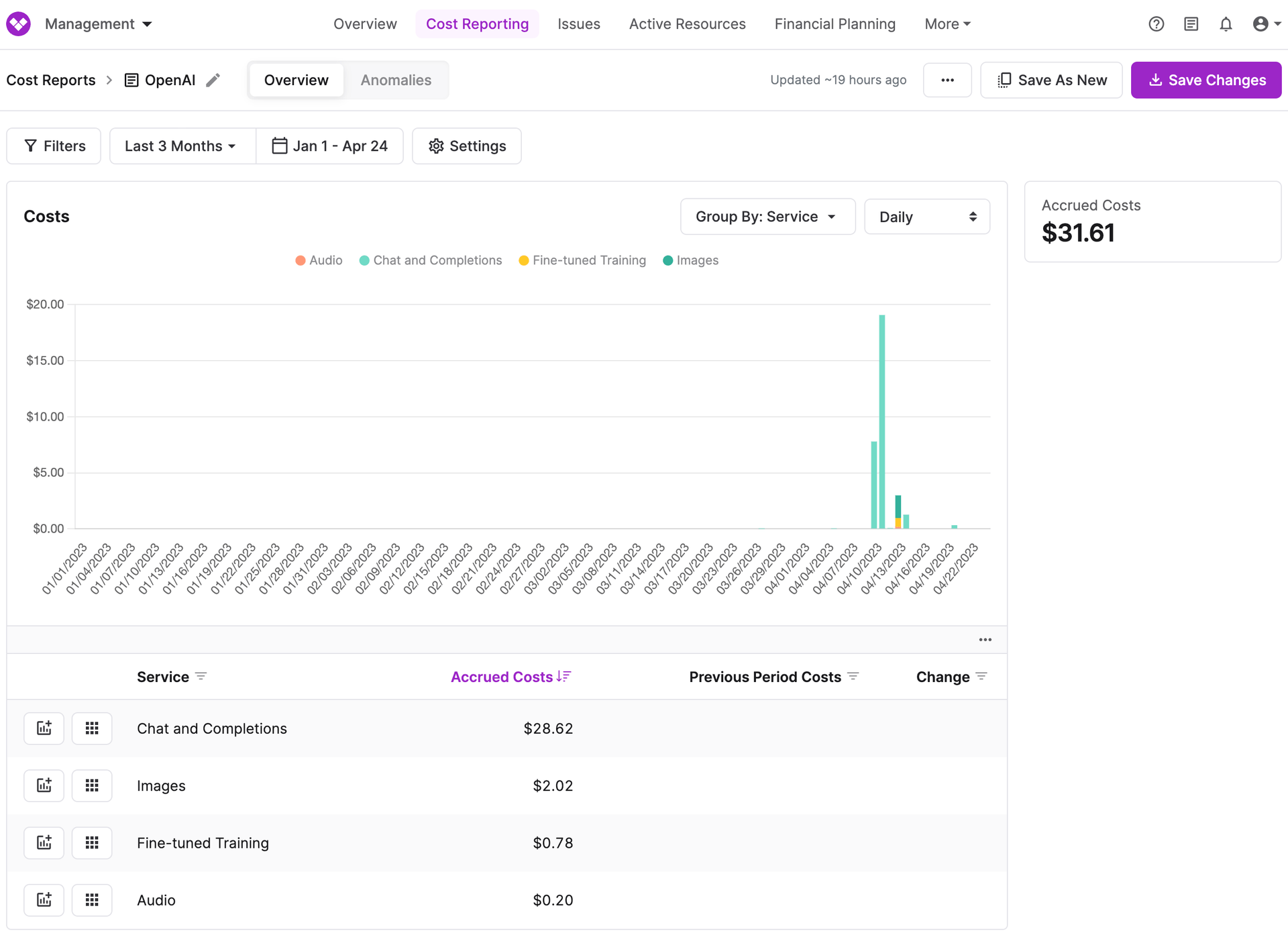
Viewing OpenAI costs on a Cost Report
Looking Ahead
We're excited about the possibilities of OpenAI's API and we're looking forward to saving our customers money on their bills. If you're interested in trying out OpenAI's API, you can sign up for an account here.
Sign up for a free trial.
Get started with tracking your cloud costs.


